[python]解析如何在Scrapy框架中存入资料到MySQL教学

在利用Scrapy框架开发网页爬虫的过程中,成功取得想要搜集的资料后,下一个步骤就是资料的储存,像是存入资料库或是档案中等,这时候,就会需要使用到Scrapy框架的项目资料模型及管道资料模型管道组件(模块),来帮助开发人员建立好维护的资料处理方式。
因此本文将继续[python]掌握Scrapy框架重要的XPath定位元素方法-第五篇文章所建立的Scrapy网页爬虫专案,来和大家分享如何将爬取到的网页资料,存入MySQL资料库,其中的重点包含:
Scrapy spider网页爬虫粗糙的项目资料模型崎cra的管道资料模型管道
一,Scrapy spider网页爬虫
假设此处想要进入搜集INSIDE硬塞的网路趋势观察网站-AI新闻网页的「文章标题」,「发布日期」及「作者」,这时候可以在这三个地方点击鼠标快捷键,选择「检查」,来检视HTML原始码,如下图:

开启Scrapy网页爬虫专案,在spiders / 的parse()方法(Method)中,利用[Scrapy教学5]掌握Scrapy框架重要的XPath定位元素方法文章中分享的xpath()方法(Method),来爬取网页中所有的「文章标题」,「发布日期」及「作者」,如下范例:

有收看上一篇文章文章知道,getall()方法(方法)回传的是一个串列(List),所以要获得其中的资料,就需要透过回回圈来进行读取,如下范例:
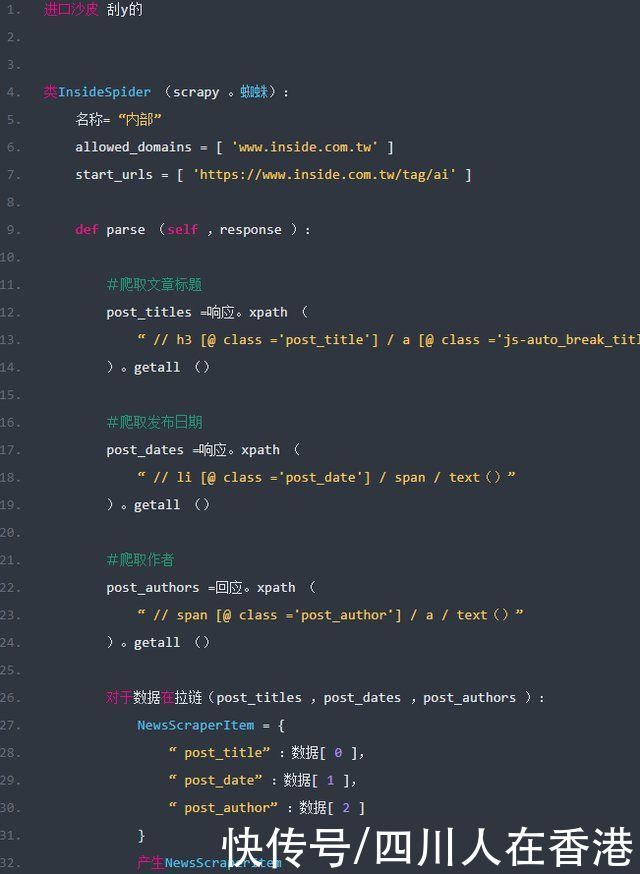
以上范例第26行,使用了zip()函数将爬取的“文章标题”,“发布日期”及“作者”串列(List)资料,打包为一个人的元组(Tuple),如下范例:
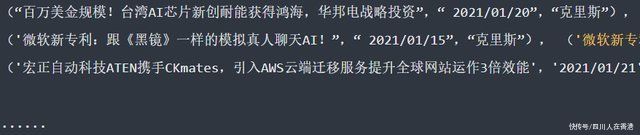
而在回圈读取的过程中,就需要定义一个物件,来分别储存每一个元组(Tuple)的“文章标题”,“发布日期”及“作者”资料,能够在“资料模型管道档案(pipeline.py )”中,进行后续资料处理使用。
这时候就需要像第27行一样,利用「资料模型档案(items.py )」中的NewsScraperItem类别(Class)来装载资料,并使用「post_title」,「post_date」及「post_author」三个栏位,来分别装载元组(Tuple)中的爬取资料,然后,透过yield关键字回传到「资料模型管道档案(pipeline.py )」中进行运用。
而NewsScraperItem类别(Class)的“ post_title”,“ post_date”和“ post_author”三个属性栏位,当前尚未定义,这也就是接下来所要进行的步骤。
二,草皮物品资料模型
Scrapy框架的item资料模型,也就是在刚刚范例中所使用的NewsScraperItem类别(Class),主要就是被定义在“资料模型管道档案(pipeline.py)”中,资料处理时所会使用到的栏位。
而本文中的「资料模型管道档案(pipeline.py)」中所要进行的资料处理,就是存入MySQL资料库,其中就会使用到「post_title」,「post_date」及「post_author」三个栏位,这当时就需要在「资料模型档案( items.py )」中定义,如下范例:
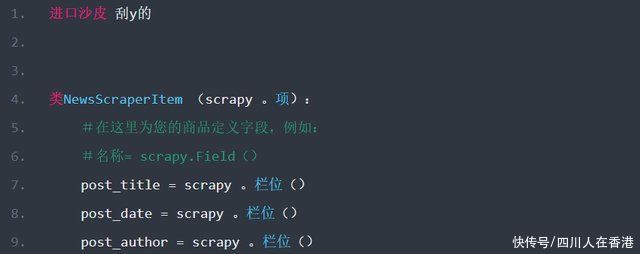
完成NewsScraperItem资料模型的定义后,接下来就可以在“资料模型管道档案(pipeline.py)”中,来访问其中所装载的资料。
三,崎cra的管道资料模型管道
在开始将Scrapy网页爬虫取得的资料写入MySQL资料库前,大家可以先参考[Python实战应用]掌握Python连结MySQL资料库的重要操作文章的第二节安装MySQL,接着,就可以建立本文需的「insideb」资料库,如下图:

设定完成后,点击右下角的应用按钮即可。这时候顶端栏会看到多了一个“ insideb”资料库,在下方的Tables(资料表),单击鼠标右键,选择“ Create Table(添加资料表) )」,如下图:
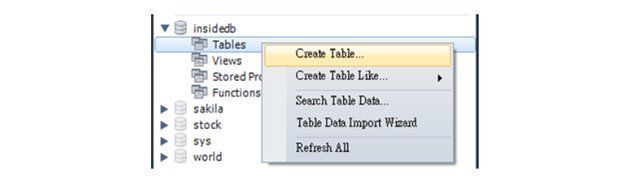
接着,输入资料表名称(posts),并在下方定义其中的栏位(Columns),包含“ post_title”,“ post_date”及“ post_author” ,如下图:
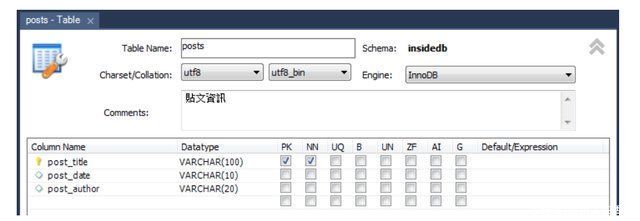
同样点击Apply按钮就完成了,如下图:
MySQL资料库建置完成,接下来,在Scrapy专案的settings.py档案中,就需要设定相关的资料库连线资讯来进行连接,如下范例: